Agentic Ambient Intelligence: Bringing AI into the Physical World
This post serves as a companion to my keynote talk, “Agentic Ambient Intelligence: Perception, Reasoning & Action,” which I recently had the pleasure of presenting at the ICLR 2026 workshops on Multimodal Intelligence and DATA-FM. It outlines the core vision and research work discussed during the session, and for those interested in the full visual walkthrough, you can access the presentation slides here.
Right now, the world is obsessed with digital agents. We see them in our IDEs writing code and in our browsers managing workflows. It’s an “in-the-screen” revolution. But if we stop there, we miss the most important part of being human: the physical world. Our most meaningful activities don’t happen in a tab; they happen in our kitchens, our workshops, and our hospitals. This is the frontier of Agentic Ambient Intelligence. Our goal is to move AI beyond passive observation and into active collaboration—building technology that doesn’t just record our lives, but “superpowers” them in real-time.
Imagine you’re wearing a pair of Smart Glasses while assembling a complex piece of machinery. You don’t need a recording of your mistake; you need the glasses to see the specific bolt you’re holding, understand your hesitation, and overlay a digital “next step” directly onto your workbench.
Or consider a residential move—a high-stress environment where a robot acts as a true expert assistant. It needs to understand ambiguous commands like “be careful with that one,” recognize that “that one” refers to the box of glassware you just taped up, and then calculate the exact physical trajectory to move it safely.
To bridge the gap between “Digital Reasoning” and “Physical Action,” we have focused our research on mastering four core pillars: Space-Time Awareness, Cross-Modal Reasoning, Active Perception, and Predictive Action.
1. Precision in Space and Time: The Strefer Engine
To be a useful partner in the real world, an agent has to understand “Where” and “When.” This sounds simple, but for AI models, it can be a minefield of ambiguity.
If you point to a specific board on the floor and ask, “Does this look level?” or refer to a mistake you made two minutes ago, the model has to anchor its reasoning to a specific spatial point (your gesture) and a specific temporal point (the past action). Most current Vision-Language Models (VLMs) treat video like a flat sequence of images, losing these crucial “anchors.”
Our hypothesis for why models struggle here is a lack of training data. It is incredibly expensive and time-consuming for humans to sit and manually label thousands of videos with precise masks and timestamps.
To break this bottleneck, we built Strefer [1], an automated data-generation engine. Instead of relying on slow human annotation, Strefer uses a modular pipeline to “self-teach.”
To achieve this, we synthetically generate data for capabilities where current models struggle—specifically, space-time referring. Thus, our strategy is to coordinate a suite of open models, each with specific, simpler capabilities which, if coordinated correctly, can synthesize the complex, multimodal instruction data needed to further train a VLM to induce space-time referring capabilities into it. As a result, Strefer generates Question-Answer pairs that include both spatial masks (highlighting the object) and timestamp references (pinpointing the moment).
By using Strefer, we scaled a set of 4,000 source videos into a large collection of 900,000 high-quality training samples. The result? A significant boost in model performance across multiple benchmarks—proving that we can teach AI the “where and when” without a massive human workforce.
I invite you to refer to our Strefer paper [1] for details of our data generation pipeline, as well as our released data-synthesis code and generated data.

2. Choosing the Right Sense: Cross-Modal Reasoning with Contra 4
In a lab, data is clean. In the real world, data is messy, conflicting, and loud.
Imagine a robot inspecting a piece of machinery. It hears a strange rattling sound (Audio), sees a tiny hairline fracture (Image), and reads a faded warning tag (Text). To act correctly, the agent must decide: Which signal matters most right now? This is the challenge of Modality Selection, and it is where even the most advanced AI often trips up.
Unfortunately, training data examples that contain multiple well aligned modalities are scarce and difficult to collect and annotate. This results in current models struggling to discern which “sense” to trust when the information is complementary or contradictory.

To address this gap, we developed Contra 4 [2], a rigorous benchmark and training set designed to test a model’s ability to weave together (or choose between) 3D data, audio, images, and video.
- Language as the Connector: Since it’s hard to find datasets where a 3D scan and an audio file are perfectly paired, we built an automated pipeline that uses language as a “universal bridge” to link different sensors together.
- The Gap: Our testing revealed a stark reality—while humans are experts at filtering sensory noise, state-of-the-art models struggle significantly.
- Fine-Tuning Insufficiency: Even task-specific fine-tuning (which boosted one model, OneLLM, from a 32% baseline to 50% accuracy) proved insufficient to achieve robust results, indicating that alternative architectural approaches are necessary.
You can find technical details in our paper [2] along with our benchmark and training data release.
3. Smarter, Not Harder: Active Video Perception (AVP)
If you’re looking for your keys in a two-hour video of your day, you don’t watch every single second at half-speed. You skip around, look for “key-looking” shapes, and zoom in when you see something promising.
However, standard AI doesn’t do this. Most models use “Passive Perception”—they process and caption every frame at a fixed rate. It’s the computational equivalent of binge-watching an entire series just to find one 10-second cameo. It’s slow, expensive, and often misses the fine details because it’s spread too thin.
We propose Active Video Perception (AVP) [3]. Instead of treating a video like a flat file to be read, AVP treats it like an interactive environment. It operates in a continuous loop:

- Plan: Based on the user’s question, the model decides where and how to look (e.g., “Check the kitchen counter at 10:15 AM”).
- Observe: It “glances” at that specific slice of time with high resolution to extract evidence.
- Reflect: It asks itself: “Do I have enough info to answer the question?” If not, it loops back and plans its next move.
Because AVP only “looks” at what matters, it achieves higher accuracy with significantly less computation. We are replacing brute-force computation with strategic evidence-seeking.
Check out our paper and code release [3] for more details.
4. Motion-Guided Generation and Control with FOFPred
The ultimate test of an agent isn’t just answering a question; it’s taking the right action. If you ask your Smart Glasses, “What should my next move be?” while fixing a bike, a text response isn’t enough. You need to see the motion—the specific arc of the wrench or the click of the gear.
Current models are stuck in two extremes. “Text-to-Video” models can create pretty pictures, but they struggle to have a sense of physical precision. On the other side, “Robot” models (VLA) are incredibly precise but require massive, expensive datasets of human experts performing every single task.

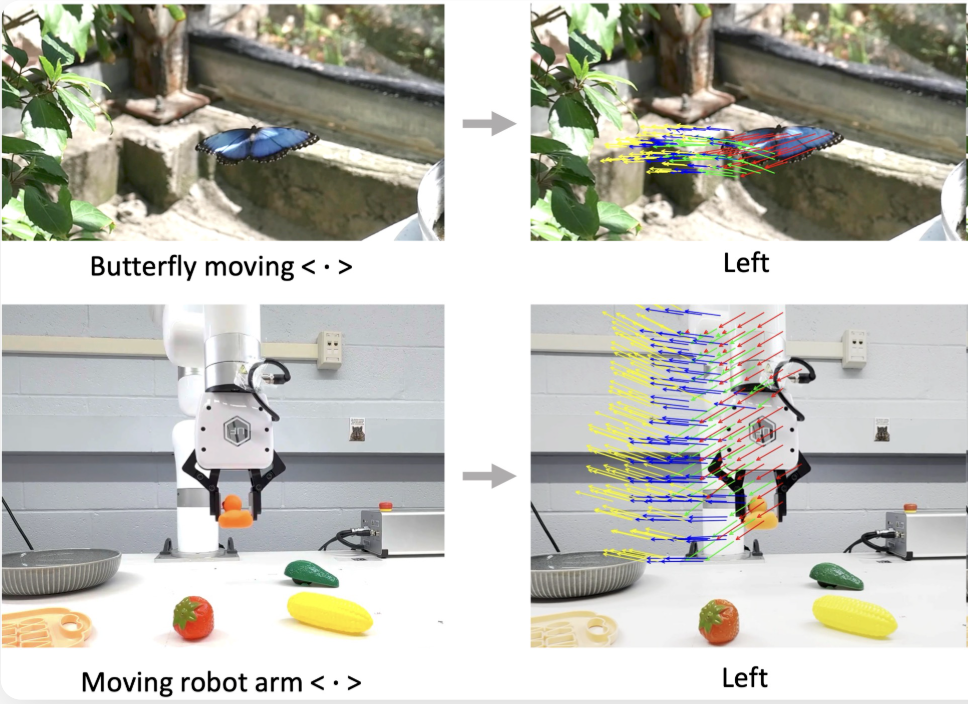
We introduced FOFPred [4] to teach AI to predict motion using the vast, “noisy” data of the internet. FOFPred learns to predict Future Optical Flow—essentially, a pixel-by-pixel map of how an object should move in the future.
- Language-Guided Motion: By converting a text command like “Pull the lever” into a visual motion representation, the model “imagines” the physical trajectory in the scene.
- Internet-Scale Learning: Because it learns from standard video-caption pairs found online, it doesn’t need specialized robot demonstrations to understand basic physics and movement.
- From Pixels to Pistons: Once the model can “see” the future motion, that model can be used for downstream tasks in video generation and robot control.
By moving beyond simple text tokens and into the realm of diffusion-based motion prediction, we are giving agents useful foresight to operate more accurately in our physical world.
The Future of Ambient Intelligence
By mastering these four pillars—Space-Time, Senses, Efficiency, and Motion—we are moving toward a world where AI isn’t just a tool on our desks, but a partner at our side.
As we look forward, we are excited about multiple research directions: how these agents can learn continuously from their mistakes, how they can collaborate with us without being intrusive, and how they can adapt to our unique, messy lives in real-time. By bridging the gap between digital reasoning and physical action, it is time to define the next frontier: true Agentic Ambient Intelligence.
I’d love to hear your thoughts on these directions—feel free to reach out to continue the conversation.
References


Enjoy Reading This Article?
Here are some more articles you might like to read next: