Spatio-Temporal Human-Object Interactions for Action Recognition in Videos
Victor Escorcia and Juan Carlos Niebles
Universidad del Norte, Barranquilla, Colombia
Summary
We introduce a new method for representing the dynamics of human-object interactions in videos. Previous algorithms tend to focus on modeling the spatial relationships between objects and actors, but ignore the evolving nature of this relationship through time. Our algorithm captures the dynamic nature of human-object interactions by modeling how these patterns evolve with respect to time. Our experiments show that encoding such temporal evolution is crucial for correctly discriminating human actions that involve similar objects and spatial human-object relationships, but only differ on the temporal aspect of the interaction, e.g. answer phone and dial phone.
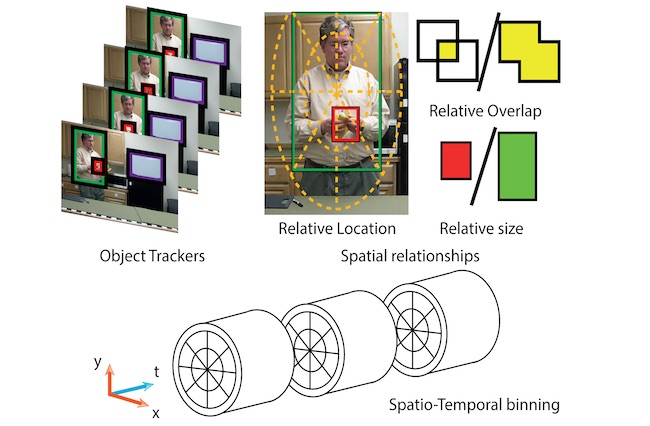
System Overview

Example Results

Given tracks of objects and humans in input videos (first column), our descriptor computes features related to the relationship between object and actor. Competing methods aggregate these features into a single spatial grid (second column), ignoring all the temporal information related to the interaction. Our descriptor aggregates this information into multiple time intervals separately. In this example, our descriptor (third column) aggregates information into 3 non-overlapping intervalsof equal length that cover the entire sequence. This enables our algorithm to leverage the temporal evolution of the human object interaction,providing a performance boost in human action recognition tasks.
Video
Resources
2013
Acknowledgments
This work was funded by a Google Research Award. V.E. is supported by a Colciencias Young Scientist and Innovator Fellowship. J.C.N. is supported by a Microsoft Research Faculty Fellowship.