What is Next in Multimodal Foundation Models?
I was panelist at the 2nd Workshop on What is Next in Multimodal Foundation Models? during CVPR 2024. The panel discussion was prompted with the question in the workshop title. In my opening statement I shared one topic that I find most interesting in this space: cross-modal reasoning. I am outlining my thoughts here.
First, the majority of research in the space of multimodality in the CVPR community really is just bi-modal, taking inputs in the form of images and language. But multimodality calls for more than that! Audio, touch, point clouds, videos are all important modalities that AI systems may be able to use to better perceive the world. Once we increase the number of modalities, cross-modal interactions start to play a role. But we do not really know much about such interactions yet for AI systems. In the case of humans, an interesting phenomenon called synesthesia happens when a person experiences one of the senses through another. For instance, a person may read a word and it triggers a taste sensation; or they may experience colors when hearing a sound. I wonder about how these kind of interactions may emerge in large multimodal models. I hope to see more analysis and studies on this in the future.
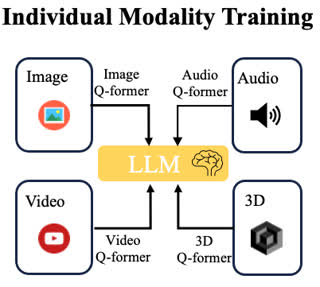
Second, in our X-instructBLIP paper [1], we looked at incorporating multiple modalities into a large multimodal model by training projections from each individual modality source into the space of LLMs. This has become a somewhat standard way to achieve multimodality. Our assumption is that we can construct a reasonable mapping from the representation space of each modality into the representation space of language. That is, the LLM space serves as a “glue” to connect all modalities into the system. This seems to be the best solution we have right now, perhaps because the LLM has been trained with so much data that it provides a very strong foundation or glue to connect other types of input data. My argument is that while this is our best current glue, it is not necessarily optimal. For instance, any modality-specific nuances that are simply non-existent or available in the LLM space are lost in the translation. Exploring alternative connecting spaces is another interesting avenue, but perhaps computationally too expensive right now.
Finally, in our paper we also observed that despite the system being trained independently for each modality and without having access to any cross-modal data, some interesting cross-modal abilities emerge during inference. To explore this, we created a test bed of the following form. Given an input from modality A and another input from modality B, we ask a natural language question such as “Which entity is more likely to be in a city?” or “Which entity is made of ceramic?”. This means the system needs to capture the semantics of the content in each input and utilize its knowledge to answer the question appropriately. While our test bed focuses on discriminative cross-modal reasoning, I think pushing for this and more advanced cross-modal abilities is a great space to study.
Multimodal AI models are still new so there is an ample space and many more questions to do research on. Let me know your thoughts!
References
Enjoy Reading This Article?
Here are some more articles you might like to read next: