Hey assistant, don't let me forget my card at the ATM!
I remember when Google Glass was announced over a decade ago. It was my first look into smartglasses. I was interested, but only followed this space at a distance. This year I was made aware of a notable successor: Ray-Ban Meta.
I may eventually become a user. I believe many of the services we access today via our smartphones will become even easier to use and to access once these smartglasses mature. For instance, we may use these glasses to search for information online, or we may give them a voice command to take a picture or video of what we are seeing at the moment.
More advanced and intelligent features will emerge. Some are already talking about features such as episodic memory, which assumes that the smartglasses are continuously capturing and recording video, and later require algorithms to index and search this comprehensive video archive for specific moments. Useful digitized visual memory. A potential privacy nightmare.
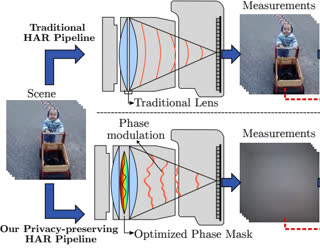
For years, I’ve been interested in the intersection between privacy-preservation and enablement of interesting, intelligent, and useful features. For instance, I looked at privacy-preserving cameras for pose estimation [1] and action recognition [2] via learnable optics. I still think this is extremely cool technology. With the advancement of smartglasses, I’m reignited to explore the space of privacy-aware and useful vision-based intelligent features.
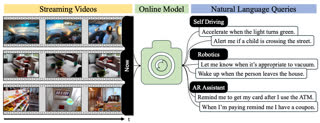
Within the context of smartglasses, instead of always-on, always-recording cameras that can retro-actively search the past, I want to focus on features that could be explicitly activated and be forward-looking only. For example, imagine you could ask your smartglasses to give you a reminder the next time a certain event happens:
“Hey assistant, remind me to get my card after I use the ATM”.
For this to work, the smartglass would capture video only after receiving a user prompt and without the need of storing the incoming video. Instead, it would process the video on-device in a streaming fashion, looking to detect the start of the event indicated by the user’s prompt.
This setting represents a new task in multimodal video understanding. The input is a user query in natural language, and the output of the system should be a detection of when the event indicated in the prompt starts to appear in the incoming video. For the system to be useful, it should detect events with low-latency (quickly after they started) and with high-accuracy (thus with a small number of false positives). But this is a very hard task: first, the input is in open natural language instead of being a set of predefined events; second, the system needs to visually identify complex events in videos which in itself is an unsolved vision problem; third, it should be fast and accurate. Our name for this task is Streaming Detection of Queried Event Start, or SDQES in short.

In our upcoming NeurIPS 2024 paper [3], we present EgoSDQES: a new benchmark to explore the SDQES task, and we evaluate a number of baseline algorithms to tackle this task. For the dataset, we leverage Ego4D videos and annotations, and augment them with an automated pipeline to generate data samples for our task. We also studied the performance of various streaming architectures and found that existing methods struggle to solve this problem. We make the benchmark available to everyone and hope to see some interesting improvements soon.
If you are attending NeurIPS in Vancouver, please visit our poster and we can discuss in person. If not, just let me know your thoughts!
References

Enjoy Reading This Article?
Here are some more articles you might like to read next: