My talks at CVPR 2026 workshops
This is an accompanying post for my CVPR 2026 workshop talks.
I share slide decks below, link each workshop page, and include a short summary of each talk.
1) Agentic Ambient Intelligence: Perception, Reasoning & Action
- Workshop: CV4Smalls 2026 @ CVPR
- Slides (PDF): Download slides
Quick summary
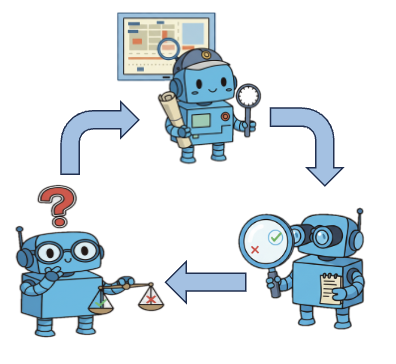
This talk presents a capability stack for real-world AI assistants that operate in physical environments.
The focus is on four ingredients: space-time grounding, long-horizon active evidence search, scalable long-context video understanding, and motion-guided action/control.
Covered papers:
- Strefer [1]
- Active Video Perception (AVP) [2]
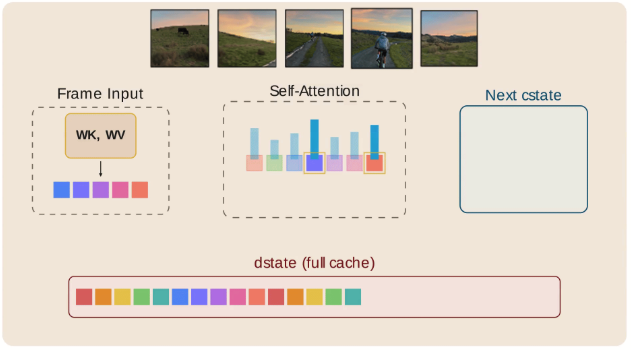
- Linear Scaling Video VLMs for Long Video Understanding [3]
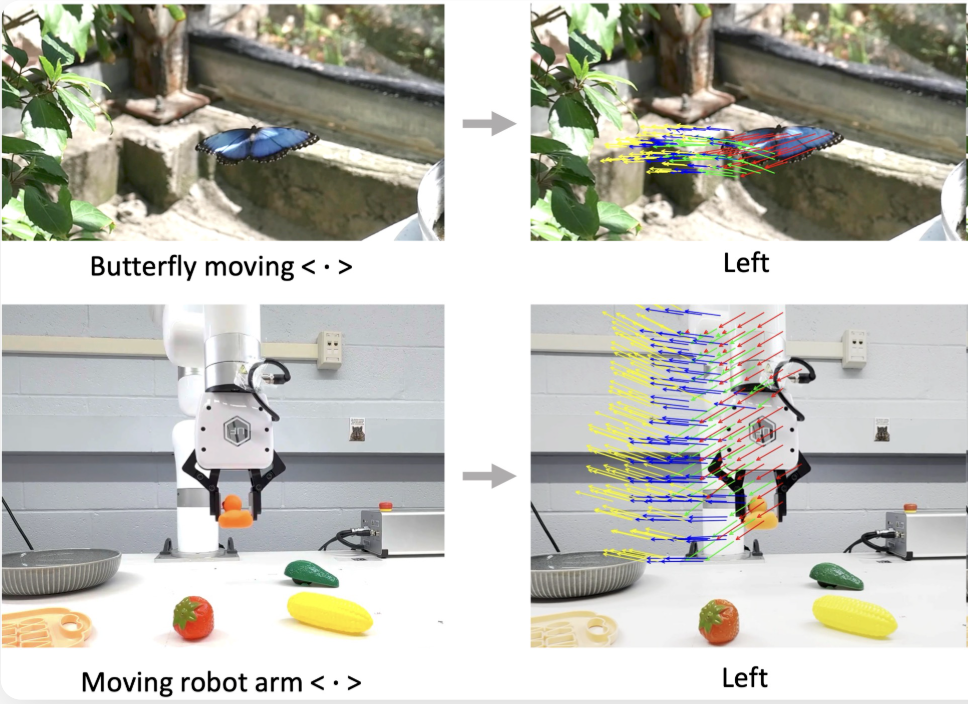
- Future Optical Flow Prediction (FOFPred) [4]
2) Scaling Transformers: Architectures, Longer Contexts, Better Data
- Workshop: T4V 2026 @ CVPR
- Slides (PDF): Download slides
Quick summary
Transformers are central to modern visual AI, but progress is increasingly constrained by three bottlenecks: expensive architecture exploration, long-context inference costs, and limited open data foundations for fair benchmarking.
This talk is organized around those three levers: post-training architecture editing, efficient long/streaming inference, and large permissively licensed datasets.
Covered papers:
- Exploring Diffusion Transformer Designs via Grafting [5]
- Linear Scaling Video VLMs for Long Video Understanding [3]
- GPIC: A Giant Permissive Image Corpus for Visual Generation [6]
3) Agentic Ambient Intelligence: Efficient Understanding & Action
- Workshop: VITA 2026 @ CVPR
- Slides (PDF): Download slides
Quick summary
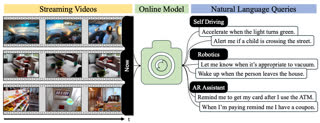
This talk focuses on building practical Virtual Intelligent Task Assistants (VITAs) that can understand user intent, process long egocentric/streaming visual input, and react in time.
The emphasis is on efficient perception loops, long-context scaling, streaming event detection, and action-oriented motion prediction.
Covered papers:
References



Enjoy Reading This Article?
Here are some more articles you might like to read next: